# Load required libraries
library(tidyverse) # For data manipulation and visualisation
library(readxl) # For data import
library(inspectdf) # For inspecting missing values
# Set the file path for the Telco Customer Churn dataset
file_path <- "r-data/telco-customer-churn.xlsx"
# Read the spreadsheet file into a tibble
telco <- read_xlsx(file_path, sheet = 1)
# Explore the dataset structure, summary statistics, and first few rows
glimpse(telco)#> Rows: 2,110
#> Columns: 21
#> $ customer_id <chr> "1452-KIOVK", "6388-TABGU", "9763-GRSKD", "3655-SNQY…
#> $ gender <chr> "Male", "Male", "Male", "Female", "Male", "Female", …
#> $ senior_citizen <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0…
#> $ partner <chr> "No", "No", "Yes", "Yes", "No", "Yes", "Yes", "Yes",…
#> $ dependents <chr> "Yes", "Yes", "Yes", "Yes", "Yes", "Yes", "Yes", "Ye…
#> $ tenure <dbl> 22, 62, 13, 69, 71, 10, 49, 47, 1, 17, 27, 72, 10, 7…
#> $ phone_service <chr> "Yes", "Yes", "Yes", "Yes", "Yes", "Yes", "Yes", "Ye…
#> $ multiple_lines <chr> "Yes", "No", "No", "Yes", "Yes", "No", "No", "Yes", …
#> $ internet_service <chr> "Fiber optic", "DSL", "DSL", "Fiber optic", "Fiber o…
#> $ online_security <chr> "No", "Yes", "Yes", "Yes", "Yes", "No", "Yes", "No",…
#> $ online_backup <chr> "Yes", "Yes", "No", "Yes", "No", "No", "Yes", "Yes",…
#> $ device_protection <chr> "No", "No", "No", "Yes", "Yes", "Yes", "No", "No", "…
#> $ tech_support <chr> "No", "No", "No", "Yes", "No", "Yes", "Yes", "No", "…
#> $ streaming_tv <chr> "Yes", "No", "No", "Yes", "Yes", "No", "No", "Yes", …
#> $ streaming_movies <chr> "No", "No", "No", "Yes", "Yes", "No", "No", "Yes", "…
#> $ contract <chr> "Month-to-month", "One year", "Month-to-month", "Two…
#> $ paperless_billing <chr> "Yes", "No", "Yes", "No", "No", "No", "No", "Yes", "…
#> $ payment_method <chr> "Credit card (automatic)", "Bank transfer (automatic…
#> $ monthly_charges <dbl> 89.10, 56.15, 49.95, 113.25, 106.70, 55.20, 59.60, 9…
#> $ total_charges <chr> "1949.4", "3487.95", "587.45000000000005", "7895.15"…
#> $ churn <chr> "No", "No", "No", "No", "No", "Yes", "No", "Yes", "Y…summary(telco)#> customer_id gender senior_citizen partner
#> Length:2110 Length:2110 Min. :0.00000 Length:2110
#> Class :character Class :character 1st Qu.:0.00000 Class :character
#> Mode :character Mode :character Median :0.00000 Mode :character
#> Mean :0.04313
#> 3rd Qu.:0.00000
#> Max. :1.00000
#> dependents tenure phone_service multiple_lines
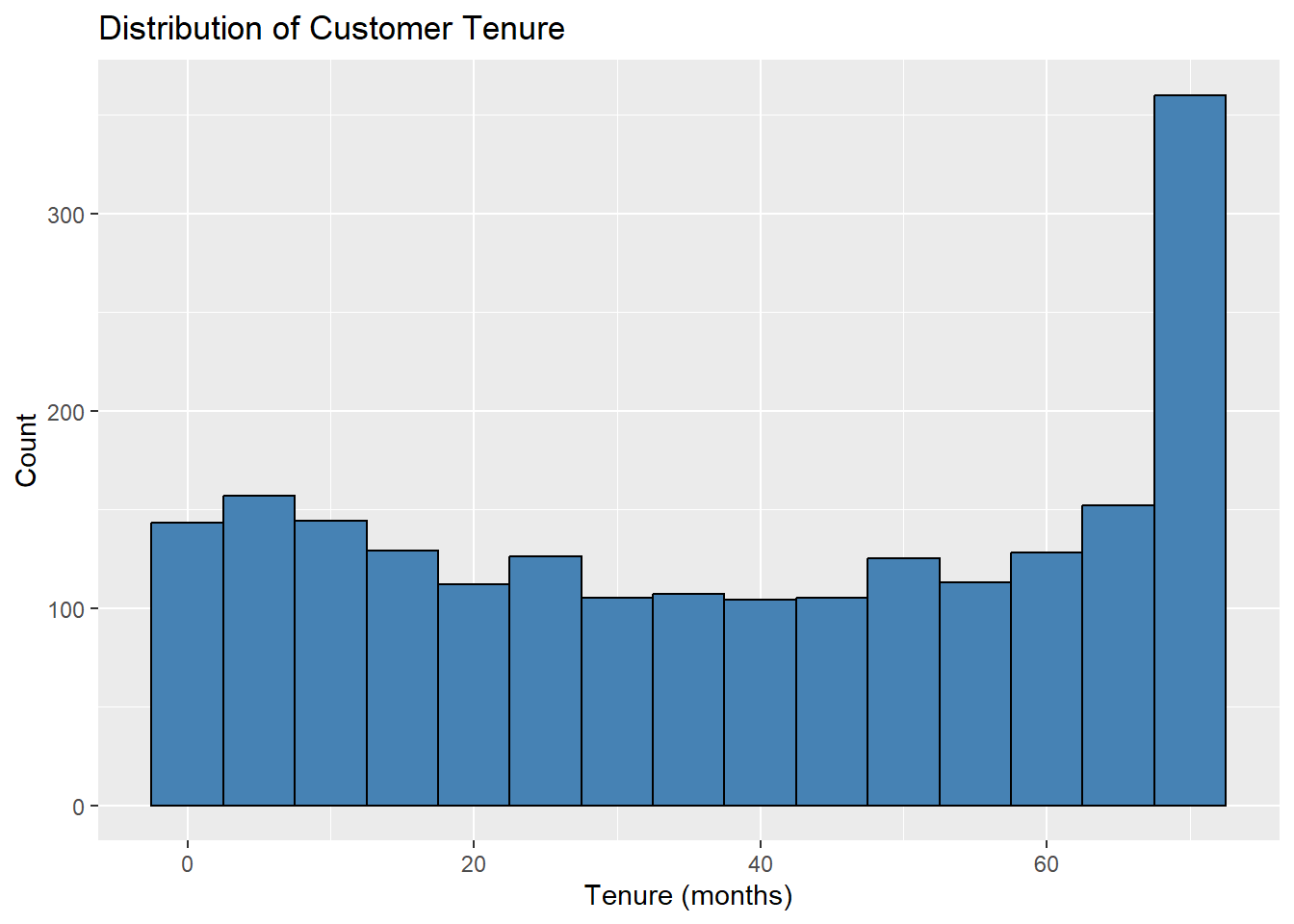
#> Length:2110 Min. : 0.00 Length:2110 Length:2110
#> Class :character 1st Qu.:16.00 Class :character Class :character
#> Mode :character Median :39.00 Mode :character Mode :character
#> Mean :38.37
#> 3rd Qu.:62.00
#> Max. :72.00
#> internet_service online_security online_backup device_protection
#> Length:2110 Length:2110 Length:2110 Length:2110
#> Class :character Class :character Class :character Class :character
#> Mode :character Mode :character Mode :character Mode :character
#>
#>
#>
#> tech_support streaming_tv streaming_movies contract
#> Length:2110 Length:2110 Length:2110 Length:2110
#> Class :character Class :character Class :character Class :character
#> Mode :character Mode :character Mode :character Mode :character
#>
#>
#>
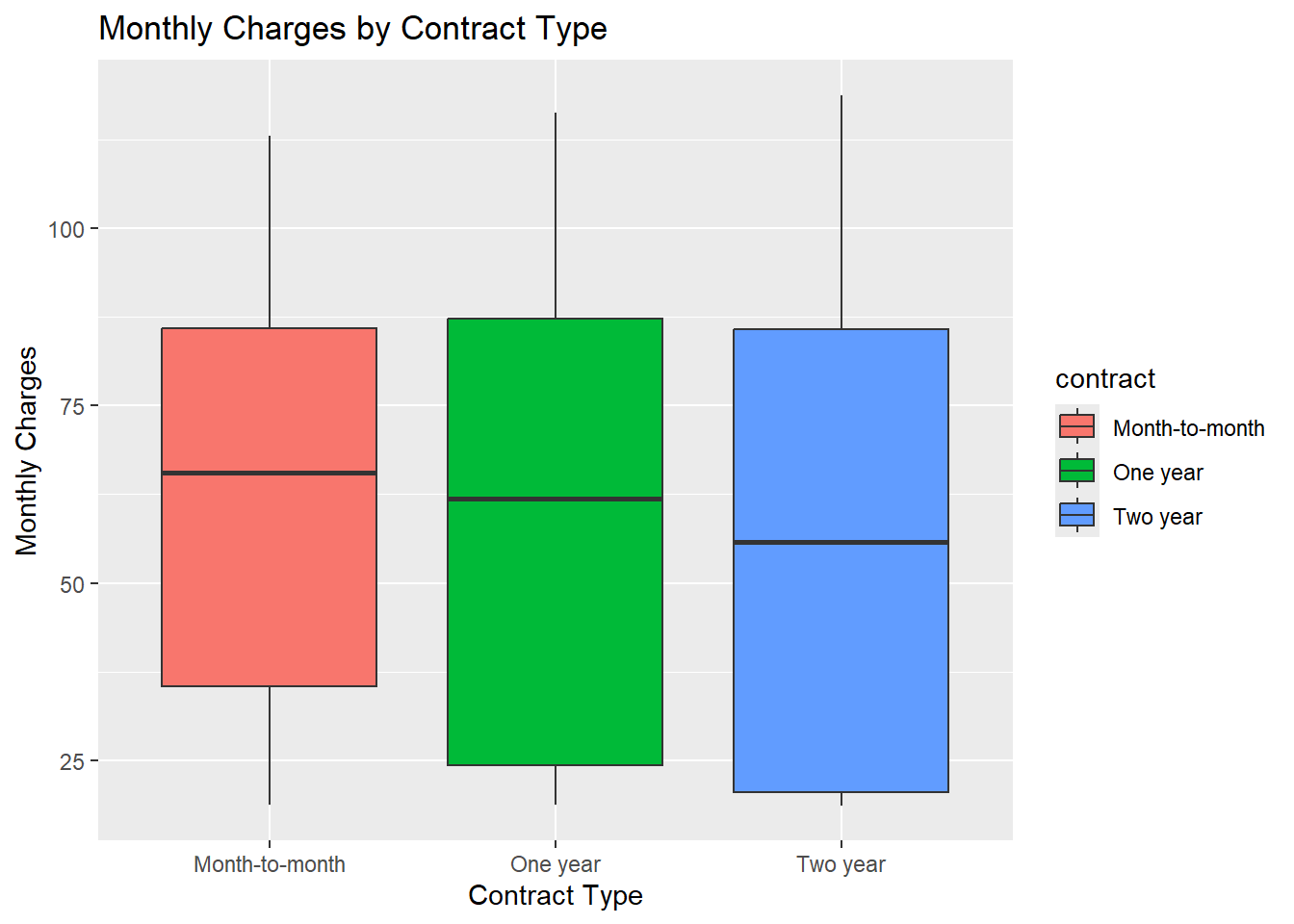
#> paperless_billing payment_method monthly_charges total_charges
#> Length:2110 Length:2110 Min. : 18.70 Length:2110
#> Class :character Class :character 1st Qu.: 24.50 Class :character
#> Mode :character Mode :character Median : 60.98 Mode :character
#> Mean : 59.52
#> 3rd Qu.: 85.95
#> Max. :118.75
#> churn
#> Length:2110
#> Class :character
#> Mode :character
#>
#>
#> head(telco)#> # A tibble: 6 × 21
#> customer_id gender senior_citizen partner dependents tenure phone_service
#> <chr> <chr> <dbl> <chr> <chr> <dbl> <chr>
#> 1 1452-KIOVK Male 0 No Yes 22 Yes
#> 2 6388-TABGU Male 0 No Yes 62 Yes
#> 3 9763-GRSKD Male 0 Yes Yes 13 Yes
#> 4 3655-SNQYZ Female 0 Yes Yes 69 Yes
#> 5 9959-WOFKT Male 0 No Yes 71 Yes
#> 6 4190-MFLUW Female 0 Yes Yes 10 Yes
#> # ℹ 14 more variables: multiple_lines <chr>, internet_service <chr>,
#> # online_security <chr>, online_backup <chr>, device_protection <chr>,
#> # tech_support <chr>, streaming_tv <chr>, streaming_movies <chr>,
#> # contract <chr>, paperless_billing <chr>, payment_method <chr>,
#> # monthly_charges <dbl>, total_charges <chr>, churn <chr># Inspect missing values for each column
telco %>%
inspect_na() %>%
print(n = 21)#> # A tibble: 21 × 3
#> col_name cnt pcnt
#> <chr> <int> <dbl>
#> 1 total_charges 11 0.521
#> 2 customer_id 0 0
#> 3 gender 0 0
#> 4 senior_citizen 0 0
#> 5 partner 0 0
#> 6 dependents 0 0
#> 7 tenure 0 0
#> 8 phone_service 0 0
#> 9 multiple_lines 0 0
#> 10 internet_service 0 0
#> 11 online_security 0 0
#> 12 online_backup 0 0
#> 13 device_protection 0 0
#> 14 tech_support 0 0
#> 15 streaming_tv 0 0
#> 16 streaming_movies 0 0
#> 17 contract 0 0
#> 18 paperless_billing 0 0
#> 19 payment_method 0 0
#> 20 monthly_charges 0 0
#> 21 churn 0 0